
When my Kohai asked “why reduce dimensions?”, the Senpai replied back “because it works!”.
This article will highlight the potential use of Principal Component Analysis (or PCA) as a useful tool in aerodynamic shape optimisation related problems. This article is not meant to serve as an introduction to PCA itself, for which a plethora of good articles already exists. The analysis is based on the data obtained in a recent study by Brahmachary and Ogawa 2021, where a multi-point multi-objective optimisation problem for scramjet intake was undertaken.
PCA is a data-driven dimensionality reduction technique. Ever since its inception in 1901, it has seen widespread use in fields such as image compression, classification, face recognition, anomaly detection, etc. The present article will focus on the use of PCA in dimensionality reduction (or data compression) and flowfield (or image) classification, for high-dimensional data obtained from Computational Fluid Dynamics (CFD) based numerical simulations.

It is often seen that aerodynamic shape optimisation (or ASO) problems targets to achieve shapes that either maximise or minimise certain performance measures, e.g., drag/lift coefficient, efficiency, etc. These scalar quantities of interest QoI themselves depend on high-fidelity flowfield data governed by partial differential equations. Consequently, one can envisage a scenario where these unique high-fidelity flowfield data are evaluated as many times as there are unique combinations of decision variables produced by the optimiser.
Decision variables: Vector of input values or parameters which determine the shape of the geometry (or scramjet intake in this case).

For typical optimisation problems with multiple objectives (i.e., multi-objective optimisation MDO) solved using evolutionary algorithms, the final optimal solution is usually more than 1. The set of optimal solutions is referred to as Pareto optimal solution. The evolutionary algorithm based optimisation starts with an initial population of solutions (or geometries) and with MDO generations, this search concludes with a Pareto optimal front. In this process from start to finish, the search algorithm evaluates multiple flowfields and subsequently determines the QoI. Processing such large ensemble of high-fidelity flowfield data is challenging and motivates the use of dimensionality reduction techniques.
Pareto optimal solution: Set of (non-dominated) optimal solutions obtained in a multi-objective optimisation problem.
Flowfield: High-fidelity data that are the discrete solutions to underlying conservation laws. These data often represent the spatial/temporal variation of field variables such as static pressure, density, velocity, temperature, etc.

Dimensionality reduction technique (e.g., PCA) can be utilised to not only compress the high-dimensional data but in the subsequent sections, it will be shown how PCA can be utilised to extract useful information in a lower-dimensional space spanned by the principal components. Particularly, this article will highlight how PCA is used as an image classifier for high-fidelity CFD flowfield data.
The crucial steps involved in PCA can be summarised as follows:
- Create the data matrix
: Every row of this matrix is composed of the nodal values of a field variable(s), e.g., static pressure. There is n number of nodes in a flowfield. Every column of this matrix corresponds to a flowfield m. Consequently,
- Compute the average or mean matrix
such that
- Subtract original data matrix from mean matrix to generate the mean-centered data
. This is necessary as computing PCA is sensitive to the variance in the data.
- Compute the covariance matrix of
. This step enables us to find out highly correlated data existing in our dataset.
- Compute eigenvectors
and eigenvalues
of the covariance matrix
. The eigenvectors
.

![\mathbf{\bar{X}} = [1, 1, 1 ... 1]^ \mathrm{'} \frac{1}{n} \sum_{i=1}^{n} \mathbf{X}_{\mathrm{i}}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5Cbar%7BX%7D%7D+%3D+%5B1%2C+1%2C+1+...+1%5D%5E+%5Cmathrm%7B%27%7D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Cmathbf%7BX%7D_%7B%5Cmathrm%7Bi%7D%7D&bg=FFFFFF&fg=111111&s=0&c=20201002)
The above steps enable us to decompose the input data matrix 

![[\mathrm{U, S, V}] = \texttt{svd(M,`econ');}](https://s0.wp.com/latex.php?latex=%5B%5Cmathrm%7BU%2C+S%2C+V%7D%5D+%3D+%5Ctexttt%7Bsvd%28M%2C%60econ%27%29%3B%7D+&bg=FFFFFF&fg=111111&s=0&c=20201002)
where 
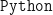
![[\mathrm{U, S, V}] = \texttt{np.linalg.svd}(\mathbf{M})](https://s0.wp.com/latex.php?latex=%5B%5Cmathrm%7BU%2C+S%2C+V%7D%5D+%3D+%5Ctexttt%7Bnp.linalg.svd%7D%28%5Cmathbf%7BM%7D%29+&bg=FFFFFF&fg=111111&s=0&c=20201002)
It now follows, 
Flowfield reconstruction:
Following the decomposition of the large data-matrix 


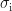
Now that we have covered the basics of PCA, we would like to see how useful it is in data compression. As mentioned earlier, the original data matrix 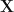



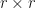


Accuracy of reconstructed 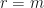




A quick look at the figures above indicates that there is a continuous decrease in



It is clear that the reconstructed flowfield and the actual flowfield (solutions of Euler equations) are completely different when just 1 PCA mode is used. However, for
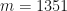

Flowfield classification:
PCA offers tremendous potential for image classification and pattern recognition. Given that a lot of data is obtained at the end of MDO, it is impractical to analyse the data as it is, which would require a 

The results from the study performed by Brahmachary and Ogawa 2021 showed that the Pareto optimal front exhibits two broad patterns, as can be observed above in the Mach number flowfield distributions, i.e., some flowfield features a distinct shock whereas others were characterised by diffused compression waves.
The above posed a question – if the higher dimensional data showed signs of distinct pattern, would they exhibit some pattern in a lower-dimensional space with a clear separation or boundary between the solutions in each cluster? To find out, it was necessary to perform PCA on the Pareto optimal solutions, which comprised of 32 unique flowfields.


PCA was performed on the data matrix formed using 24 random flowfields chosen from the repository of 32 Pareto optimal solutions. The cumulative sum of the singular values, as well as the singular values themselves, show that within the first few PCA modes, significant energy or variance is captured by the principal components. As such, it is hoped that the first three principal components will be enough to represent the high-dimensional data and extract useful information.

The above figure shows all 24 cases in terms of their first three principal components. It demonstrates a clear dissociation between the solutions within each group, i.e., there is a tendency to form clusters. In other words, the unique flowfield characteristics that were seen earlier in the higher-dimensional data within each group of solutions (i.e., diffused compression waves and a strong oblique shock), is also retained in a lower dimensional space spanned by just three principal components. This goes on to show that such approaches can be used for image (or flowfield) classification when it might be difficult to do so for the raw data.
This analysis is part of a study undertaken in the Department of Aeronautics & Astronautics, Kyushu University, in collaboration with Mr. Ananthakrishnan Bhagyarajan (Post graduate student, UCLA) and Dr. Hideaki Ogawa (Associate Prof., Kyushu University).
Useful References:
- Data-Driven Science and Engineering by Brunton, S.L., Kutz, J.N.
- A tutorial on Principal Component Analysis, Lindsay I. Smith


